Serving 其實包括了很多 Load Balance, Micro service architecture design 和 data flow design,所以衡量的標準大多也在 High Efficiency, High Reliability 和 High throughput 間去做和量,我任何這要完全交給 Data Scientist 負擔難免過於沈重,但知道 Serving 可能會遇到的難點是在設計機器學習方案中很重的一環,所以接下來會花五天的時間介紹一下 Serving 會遇到的幾個挑戰,首先我們先介紹一些常用的名詞,
上述大概提到了幾個我認為比較重要的概念,但對於 Serving 我認為核心的問題是,你 Model 做 Inference 需要多少時間?更進一步說
由於我們的例子: Account Takeover Detection 本質就是一個 XGBoost Model,在 Inference 環節的 Latency 非常的低,主要的 IO (Model Loading) 可以透過像是 Singleton 的方式來避免重複讀取,所以這裡我們會將 Serving 環節的重點放在 Feature Pipeline:
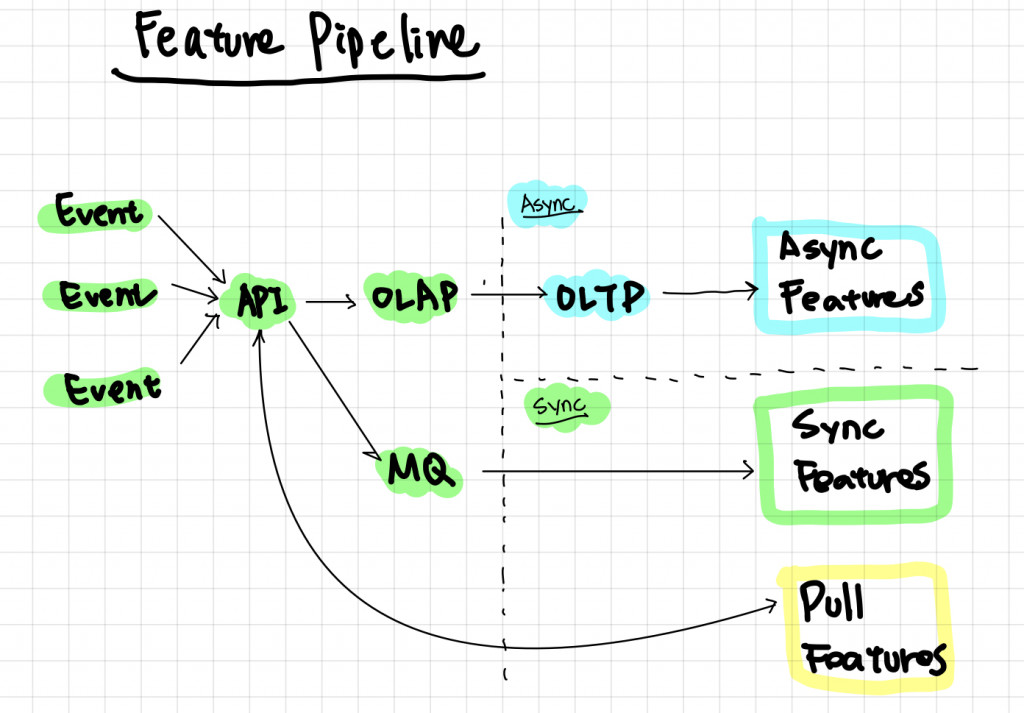
我們將整個 Feature Pipeline 分長三個主要來源
除了將上述的分類外,我們會將 Pipeline 分成 Computational Component 和 Storage Component 來設計,那就讓我們在接下來的四天來介紹 Serving Section 吧!


 iThome鐵人賽
iThome鐵人賽